

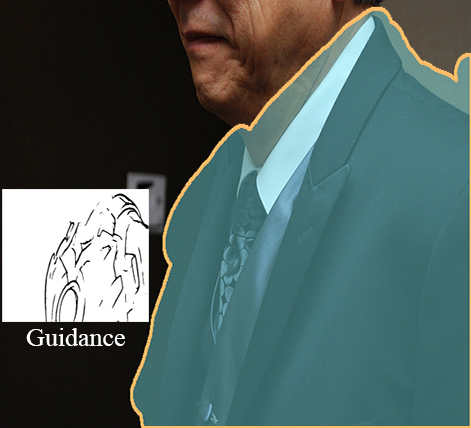
MaGIC supports diverse modalities such as text, canny edge, sketch, segmentation, reference image, depth, and pose as guidance. It also accommodates customizable combinations of these modalities without additional training, allowing for arbitrary multi-modality, enabling tasks like image in/out-painting, local editing, and generalizing to image generation.
"A man is wearing a gray collared shirt under the sunset."


"Three Groot are standing."


"Two men ride cows in the sea, Van Gogh."
The vanilla image completion approaches are sensitive to the large missing regions due to limited available reference information for plausible generation. To mitigate this, existing methods incorporate the extra cue as a guidance for image completion. Despite improvements, these approaches are often restricted to employing a single modality (e.g., segmentation or sketch maps), which lacks scalability in leveraging multi-modality for more plausible completion.
In this paper, we propose a novel, simple yet effective method for Multi-modal Guided Image Completion, dubbed MaGIC, which not only supports a wide range of single modality as the guidance (e.g., text, canny edge, sketch, segmentation, reference image, depth, and pose), but also adapts to arbitrarily customized combination of these modalities (i.e., arbitrary multi-modality) for image completion.
For building MaGIC, we first introduce a modality-specific conditional U-Net (MCU-Net) that injects single-modal signal into a U-Net denoiser for single-modal guided image completion. Then, we devise a consistent modality blending (CMB) method to leverage modality signals encoded in multiple learned MCU-Nets through gradient guidance in latent space. Our CMB is training-free, and hence avoids the cumbersome joint re-training of different modalities, which is the secret of MaGIC to achieve exceptional flexibility in accommodating new modalities for completion. Experiments show the superiority of MaGIC over state-of-arts and its generalization to various completion tasks including in/out-painting and local editing.



"A big rocket stands behind a man."


"Handsome man."


"The Batman is standing."


"The Stormtrooper is skiing."

"A man is wearing red-and-golden armor, Ironman style, lighting on the chest."


"Stormtrooper is standing on the beach with a surfboard."

@article{yu2023magic,
title={MaGIC: Multi-modality Guided Image Completion},
author={Yu, Yongsheng and Wang, Hao and Luo, Tiejian and Fan, Heng and Zhang, Libo},
journal={arXiv preprint arXiv:2305.11818},
year={2023}
}

